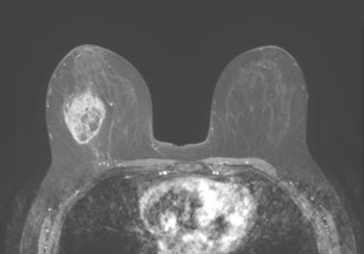
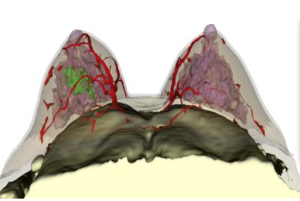
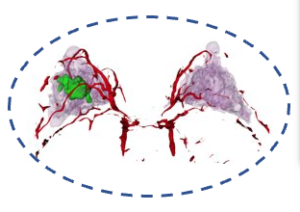
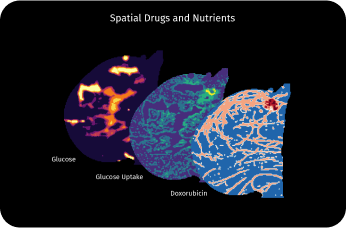
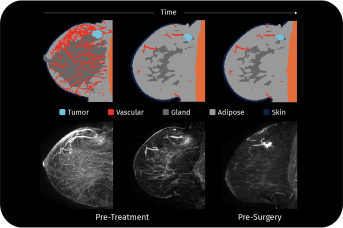
Spatial Biophysics
By integrating spatial biophysics into our technology, our research-use 3D models are designed to capture a tumor's physical, chemical, and biological information at multiple scales. Every region of the tumor's chemical concentration continually updates to model transport, reactions, metabolic behavior, and varying drug concentrations that can affect how tumor cells respond. Our 3D research models provide insights into tissue growth or decline responses, playing a pivotal role in informing cancer treatment.





")



")



")



")




")

")